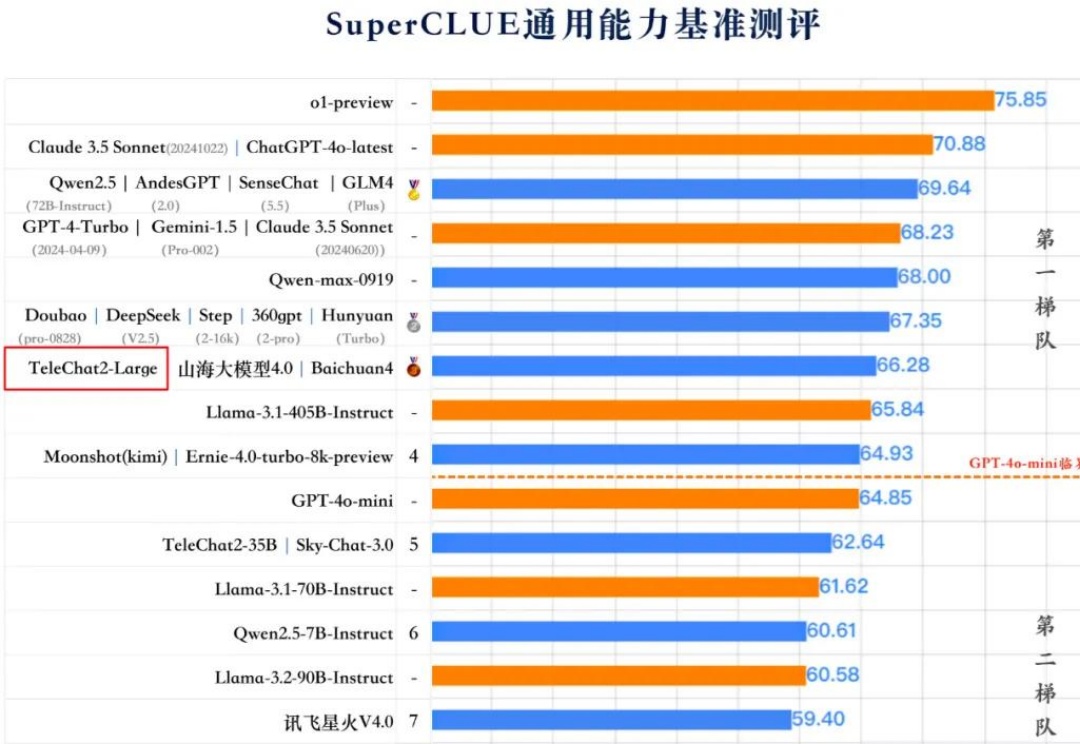
11月中国AI大模型平台排行榜
11月中国AI大模型平台排行榜有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。
来自主题: AI资讯
9213 点击 2024-12-10 11:38
 搜索
搜索
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。
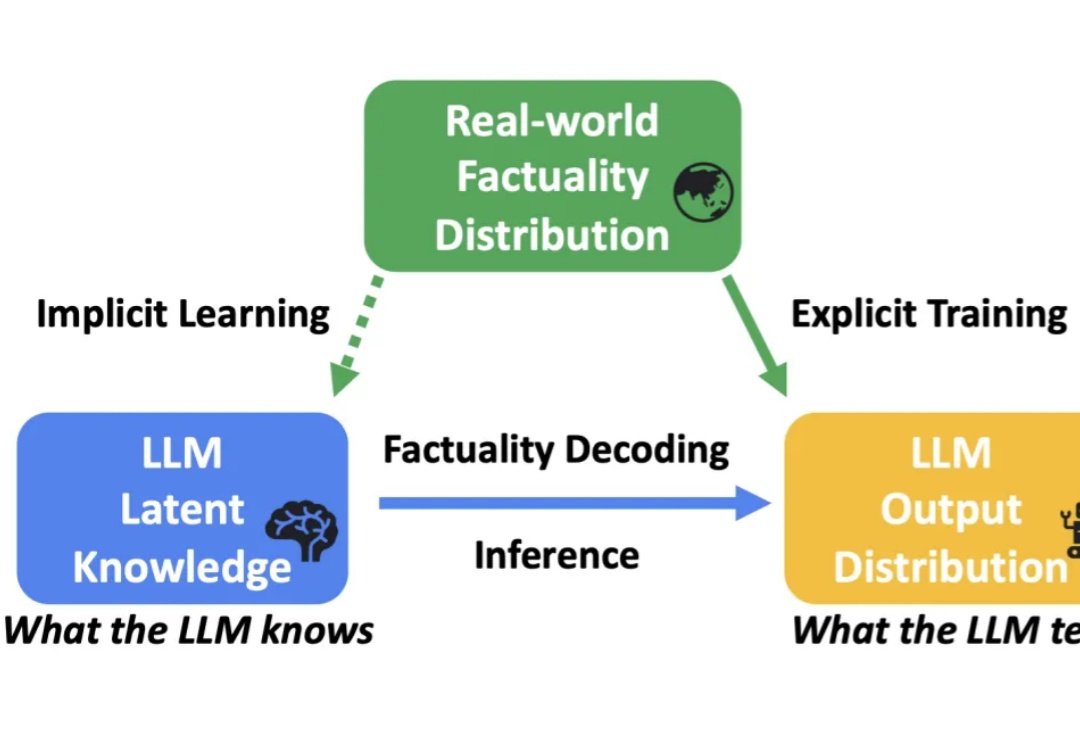
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
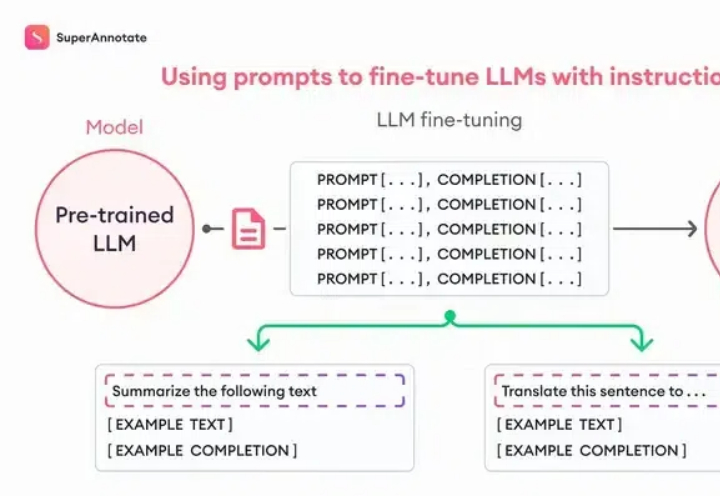
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。

2024 年即将结束,今年行业对 AI 的论调也基本尘埃落定.相比 2023 年的多个重磅发布,2024 年是模型能力的小年,但 AI Agent 却是实在的大年。
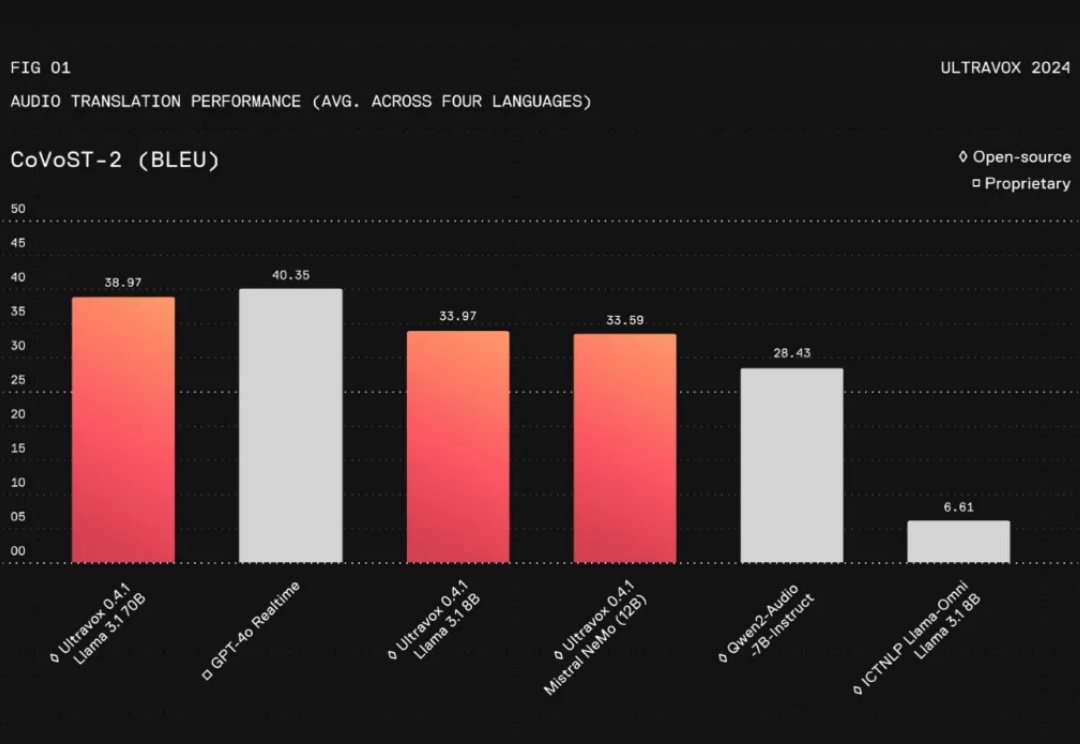
在人工智能领域,与AI进行无缝的实时交互一直是开发者和研究者面临的一大挑战。特别是将文本、图片、音频等多模态信息整合成一个连贯的对话系统,更是难上加难。尽管像GPT-4这样的语言模型在对话流畅性和上下文理解上取得了长足进步,但在实际应用中,这些模型仍然存在不足之处:
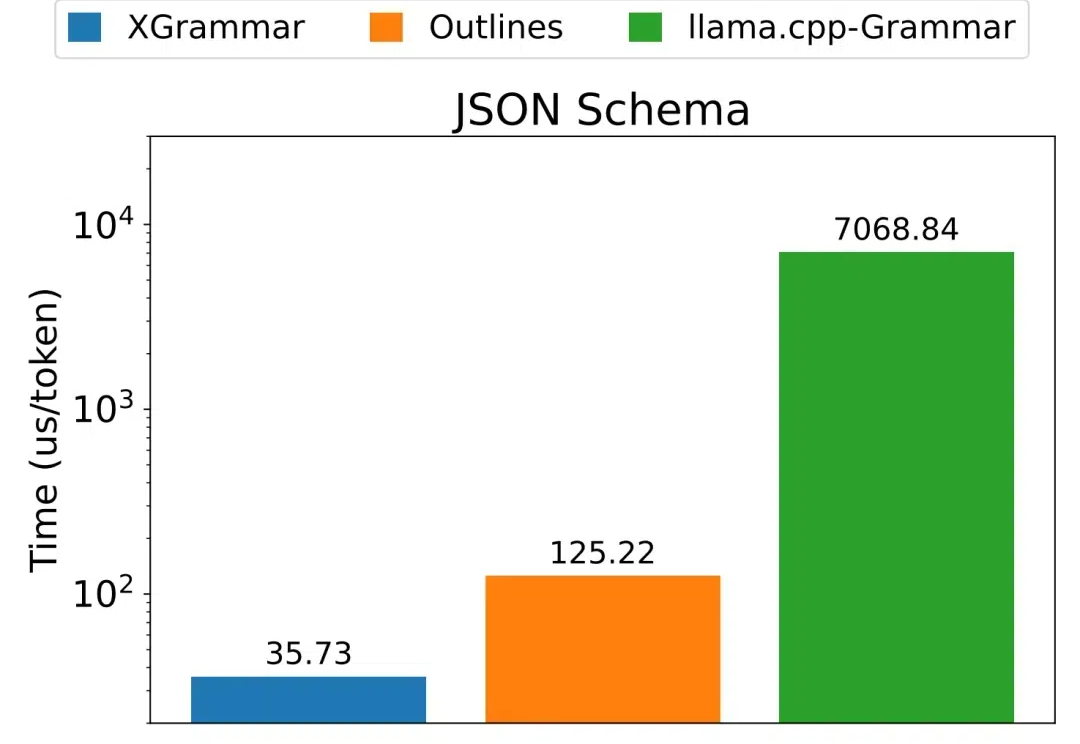
不管是编写和调试代码,还是通过函数调用来使用外部工具,又或是控制机器人,都免不了需要 LLM 生成结构化数据,也就是遵循某个特定格式(如 JSON、SQL 等)的数据。 但使用上下文无关语法(CFG)来进行约束解码的方法并不高效。针对这个困难,陈天奇团队提出了一种新的解决方案:XGrammar。

各位大佬,激动人心的时刻到啦!Anthropic 开源了一个革命性的新协议——MCP(模型上下文协议),有望彻底解决 LLM 应用连接数据难的痛点!它的目标是让前沿模型生成更好、更相关的响应。以后再也不用为每个数据源写定制的集成代码了,MCP 一个协议全搞定!

Hugging Face 上的模型数量已经超过了 100 万。但是几乎每个模型都是孤立的,难以与其它模型沟通。尽管有些研究者甚至娱乐播主试过让 LLM 互相交流,但所用的方法大都比较简单。
随着开源数据的日益丰富以及算力价格的持续下降,对于个人或小型机构而言,预训练一个小型的 LLM 已逐渐成为可能。开源中文预训练语言模型 Steel - LLM 就是一个典型案例,其模型参数量与数据量并非十分庞大,基本处于参数量为 B 级别、数据量为 T 级别的规模。